Problem Statement
A developer has already done the hard part: written the application to meet business requirements, containerized it, and prepared it for deployment. The next conversation with the platform team often sounds like this:
- How many replicas do you need?
- Should the workload span availability zones?
- Does it need single-region or multi-region resiliency?
- Does it need a public endpoint or only internal ingress?
- Does it depend on managed services?
- What storage class, throughput, or IOPS does it need?
- Has the image been scanned for vulnerabilities?
...and the questions keep coming.
These are valid questions. They are also the wrong questions to ask every application team in raw infrastructure terms. In defence of developer teams, it is not that they cannot be skilled in this domain; it is just not their focus, nor should it be. Their focus should be on delivering solutions that meet business needs.
Most developers are expressing intent, not platform topology. They want to say things like "deploy this stateless service in the most cost-efficient manner" or "run this service with high availability and expose it through ingress." The platform team, meanwhile, must translate that intent into replicas, zones, networking, policies, storage, security controls, and operational defaults.
If the platform hides everything, it becomes a black box and a ticket queue. If the platform exposes native Kubernetes primitives directly, every team must become part-time Kubernetes experts. Neither extreme matches the product mindset that platform engineering requires.
The ideal experience looks more like the Cloud Foundry model: run cf push, and the application is deployed, configured, and running — no further actions.
From Microsoft's platform engineering guidance:
"Teams working on platform engineering need to think of themselves as product owners of the internal developer platform, and developers as the end customer."
If developers are the customer, the key question becomes: what is the contract between the platform team and the application team?
Solution
One useful answer is to make that contract explicit.
A good platform API should ask developers for the minimum information needed to capture intent, while allowing the platform team to encode organizational standards behind the scenes. Defaults for topology, security, networking, observability, storage, and lifecycle management should live in the platform, not in every individual application manifest.
The Contract Platform Teams Actually Need
In practice, developers usually describe outcomes, not infrastructure. A few examples:
| Developer intent | What the platform must decide |
|---|---|
| Deploy a stateless app at lowest cost | region placement, replica count, storage defaults, ingress exposure, image policy |
| Deploy a stateless app with single-region HA | zone spread, minimum replicas, disruption policy, service exposure, health checks |
| Deploy a stateless app across regions | regional topology, traffic routing, failover behavior, external dependencies, operational guardrails |
The platform team's job is not just to provision resources. It is to provide a stable, governed API that translates these intents into repeatable implementations.
Why kro Is Interesting Here
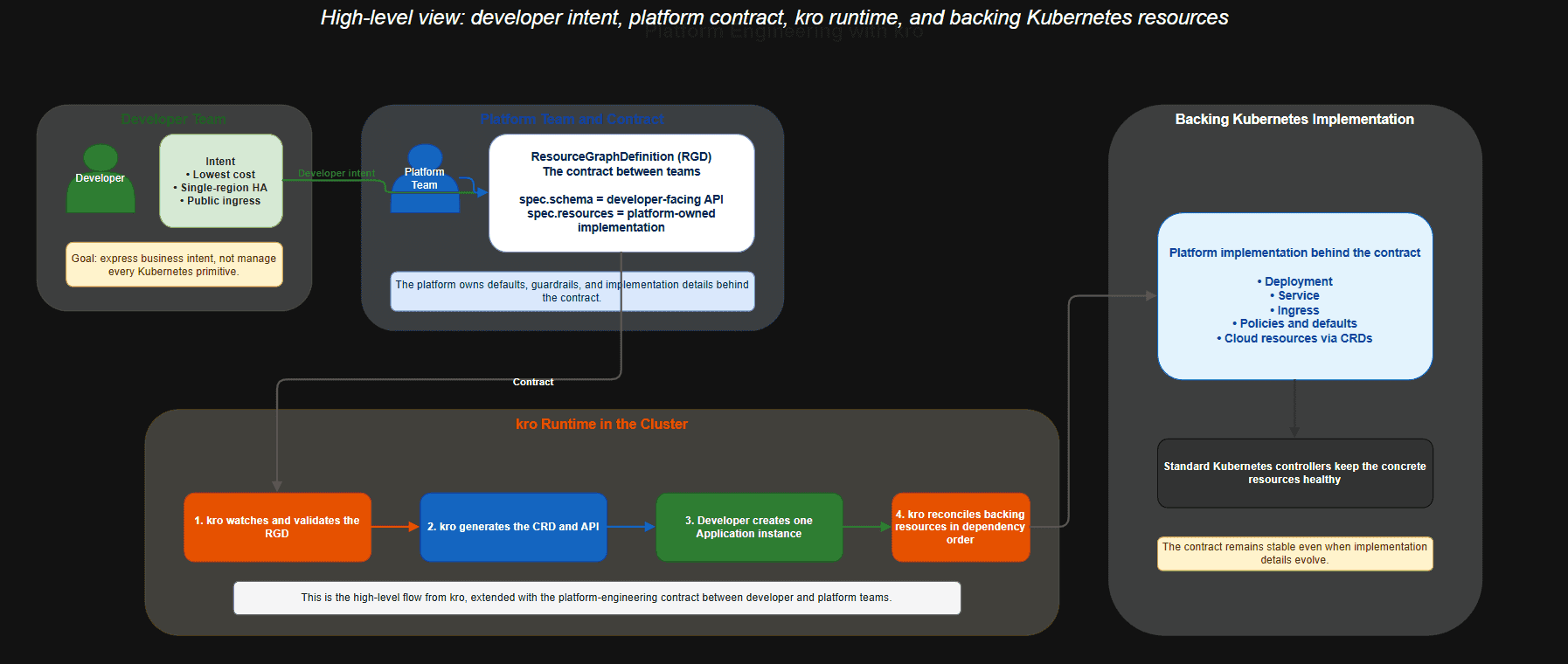
This is where kro, the Kubernetes Resource Orchestrator, fits well.
It is important to note that kro is still in alpha, but it is encouraging that it is under Kubernetes SIG and has a clear roadmap.
kro lets platform teams define a higher-level Kubernetes API that represents the contract they want developers to use. Instead of asking application teams to manage Deployments, Services, Ingresses, ConfigMaps, policies, and supporting resources directly, the platform team can expose a single custom resource such as Application, WebApp, or ServiceInstance.
Under the covers, kro is building a reusable API out of standard Kubernetes resources and existing controllers. It is also notable because it is a vendor-neutral effort under Kubernetes SIG Cloud Provider, with contributions from AWS, Google, and Microsoft to solve a common platform problem.
ResourceGraphDefinition as the Contract
The core kro concept is the ResourceGraphDefinition, or RGD.
An RGD has two important sides:
| RGD section | Primary audience | Purpose |
|---|---|---|
spec.schema |
Developer or application team | Defines the consumer-facing API and the fields developers are allowed to set |
spec.resources |
Platform team | Defines the actual Kubernetes resources, defaults, wiring, and dependencies that implement the contract |
This split is what makes kro useful for platform engineering. The platform team can keep the consumer-facing schema simple while still encoding opinionated implementation details behind it. That design should not happen in isolation. The best RGD is the result of a conversation with application teams about what inputs they actually understand and what guarantees the platform must provide.
kro does not replace RBAC, policy engines, or admission controls. It complements them. RBAC still governs who can do what. Tools such as Gatekeeper or Kyverno can still enforce policy. GitOps tools can still deliver manifests. kro's role is different: it gives the platform a cleaner API surface.
How kro Works
At a high level, the flow looks like this:
- The platform team creates a
ResourceGraphDefinitionthat describes a new API. - kro watches
ResourceGraphDefinitionobjects through its RGD reconciler and reacts when an RGD is created or updated. - kro validates the schema, checks referenced resource types, type-checks CEL expressions, and infers dependencies between resources.
- kro creates or updates the generated CRD and registers the instance handler with the dynamic controller.
- Developers create instances of that API, such as an
Applicationobject. - kro creates and manages the underlying resources in dependency order.
- Standard Kubernetes controllers continue reconciling each concrete resource after kro creates it.
That matters because the developer interacts with a simple, platform-owned API, while the cluster still benefits from normal Kubernetes reconciliation patterns.
Conceptually, the control flow is:
Platform team defines RGD
->
RGD reconciler watches the RGD
->
kro validates and creates or updates the generated CRD
->
kro registers the instance handler with the dynamic controller
->
Developer creates an instance of the new API
->
kro reconciles Deployments, Services, Ingresses, and other resources
->
native Kubernetes controllers keep each resource healthyAn instance becomes the single source of truth for the deployed application. If managed resources drift, kro can detect that drift and reconcile them back toward the desired state. This is one of the reasons kro feels more like a platform API than a one-time templating step.
Where kro Fits Relative to Helm, Kustomize, GitOps, Crossplane, and Policy
kro should not be framed as a replacement for the rest of the platform stack. It is better understood as a complementary layer.
| Tool or pattern | Primary role | Where kro fits |
|---|---|---|
| Helm | Packaging and templating software | Helm can install platform components, including kro itself; kro can expose simpler APIs to application teams |
| Kustomize | Overlay and patch Kubernetes YAML | Kustomize remains useful for environment-specific manifest customization; kro sits above that by defining the API developers consume |
| Flux or Argo CD | Git-driven delivery and reconciliation | GitOps can apply RGDs and instances; kro handles the runtime composition inside the cluster |
| Gatekeeper or Kyverno | Policy enforcement | Policy tools validate or block unsafe configurations; kro defines the abstraction developers use |
| Crossplane or cloud operators such as ASO | Managing cloud resources as Kubernetes objects | kro can compose those resources into higher-level application APIs when needed |
| Custom CRD plus controller | Fully custom Kubernetes API and reconciliation logic | kro covers the common case of composing and wiring resources without writing and maintaining controller code |
The most important distinction is this: Helm, Kustomize, Flux, and Argo CD primarily work at the YAML delivery layer. They template manifests, patch them, or sync them from Git, but the consumer still needs to understand the underlying Kubernetes resources.
kro works at the API layer. Instead of handing developers a Deployment, Service, Ingress, and supporting YAML, the platform team can hand them a single higher-level resource with a cleaner schema, defaults, and validation.
| Comparison point | YAML-level tools | kro |
|---|---|---|
| What developers see | Raw Kubernetes manifests | A higher-level custom resource such as Application |
| Validation model | Usually at deployment time | Static validation when the RGD is created |
| Dependency handling | Mostly manual or implied | Inferred automatically from CEL expressions |
| Drift correction | GitOps sync or manual correction | Continuous reconciliation of instances and managed resources |
This is also why kro can reduce engineering effort compared with building a custom CRD and controller from scratch. If the goal is to compose and wire Kubernetes resources into a simpler platform API, kro lets platform teams do that declaratively in YAML and CEL instead of writing, testing, packaging, and maintaining controller code.
This layering is important. Platform engineering rarely has a single magic tool. The goal is to combine the right tools so developers interact with a clear product surface instead of a pile of low-level primitives.
Why This Matters for Platform Engineering
A common criticism of Kubernetes is that it is too complex. There is some truth to that, but the alternative is not a simpler world. Without a consistent API layer, teams end up dealing with VM provisioning, bespoke scripts, vendor-specific consoles, inconsistent deployment patterns, and a growing amount of tribal knowledge.
The better answer is not to eliminate Kubernetes primitives altogether. It is to concentrate that complexity in the platform so application teams do not have to absorb all of it. kro helps by letting platform engineers define simpler, opinionated APIs on top of the Kubernetes model rather than exposing every primitive directly.
That is the platform engineering angle that matters most: not just automation, but product design.
Summary
One of the hardest parts of platform engineering is deciding where the contract should sit between developer intent and platform implementation. Ask developers to work directly with every Kubernetes primitive and the cognitive load becomes too high. Hide everything behind tickets and the platform becomes a bottleneck.
kro offers a useful middle path. It lets platform teams define a clean API for common deployment patterns, encode organizational standards behind that API, and keep Kubernetes reconciliation working in the background. In that sense, kro is not just a deployment convenience. It is a way to productize part of the platform.
In the next part, I will walk through concrete scenarios for that contract, such as cost-optimized stateless deployments, single-region high availability, and ingress-enabled services, and show how kro can model them.
Note: This blog is inspired by kro.run, the Kubernetes Podcast episode linked below, and several other CNCF kro-related presentations. The key emphasis is that kro can play a significant role in platform engineering.